
最近的Google I/O大会很是热闹。
在大会的最后一日,Alphabet董事长John Hennessy 亲口承认:Google Duplex已经在预约领域通过了图灵测试。
通过图灵测试!
多么令人兴奋的六个字。被人工智能所改变的世界蓝图仿佛就在我们眼前铺展。
人工智能成果喷薄爆发以来,热门领域除了机器学习,还有作为计算机语言学、人工智能和数理逻辑的交叉学科——机器翻译。
机器翻译起源于何时?如今发展到了什么程度?
国内在机器翻译上有哪些研究成果,又有哪些公司推出了令人惊叹的落地应用?
在其发展道路上,有哪些大牛发表了哪些成果,推动了地球人无障碍沟通的梦想计划?
未来,机器翻译将可能在哪些领域进行深耕?其发展趋势如何?
这些问题的答案,你都可以在未来一周内找到。
首先,我们需要了解一下机器翻译是如何兴起的。
蹒跚起步
Warren Weaver说:我觉得机器翻译可行
于是全世界都开始搞机器翻译
1946年,第一台数字电子计算机诞生。从那以后,人们就开始思索如何运用计算机代替人从事翻译工作的问题,甚至在此之前,图灵就已经开始思考计算机是否能够进行思维这一问题。
三年之后——1949年,我国正式建立,机器翻译思想也正式提出:Warren Weaver发表《翻译》备忘录,这也被视为机器翻译初始阶段的第一件标志性事件。
 Warren Weaver
Warren WeaverWarren Weaver在备忘录里展现了机器翻译的可计算性,并提出了两个主要观点。
第一个观点:他认为翻译类似于解读密码的过程,“翻译即解码”。
第二个观点:他认为原文与译文“说的是同样的事情”。
因此,当把语言A翻译为语言B时,就意味着从语言A出发,会经过某一“通用语言”或“中间语言”(可以假定这个语言是全人类共同的),最终到达语言B。
1954年,美国乔治敦大学(Georgetown)在IBM的协同下,进行了英俄翻译实验,开始了在翻译自动化方面的尝试。这是机器翻译发展初始阶段的第二件标志性事件。
总体来说,这一阶段人们头脑中已经形成了机器翻译的概念,并且已经可以意识到利用语法规则的转换和字典来实现翻译目的。
人们乐观地认为,只要通过扩大词汇量和语法规则,在不久的将来,机器翻译问题会比较完美地得以解决。
所以在此之后的很长一段时间,全球各国大力支持机器翻译项目,一个机器翻译研究的高潮就此形成。
发展冷却
ALPAC说:我觉得机器翻译不行
于是大家又不搞机器翻译了
蓬勃发展17年之后,机器学习迎来了第一个发展低谷。
1966年11月,美国语言自动处理咨询委员会(ALPAC)公布著名的ALPAC报告,从速度、质量、花费、需求等各个角度,几乎是全方位地给给机器翻译研究工作浇了一盆凉水。
APLAC对当时的各个翻译系统进行了一次评估,并在报告提出,机器翻译的译文质量明显要远低于人工翻译。
难以克服的“语义障碍”是当时机器翻译遇到的问题,在报告中,ALPAC全面否定了机器翻译的可行性,并建议各大机构停止对机器翻译的投资和研究。
尽管这份报告的结论过于仓促、武断,但是这一阶段关于机器翻译的研究的确没有解决许多至关重要的问题,并没有对语言进行深入的分析。
此后在世界范围内,机器翻译出现了空前的萧条局面。
重启篇章
大公司说:我们觉得还是得重新搞一下
于是机器翻译得以复苏
20世纪80年代末,由于微处理器的出现,计算机能力获得了突飞猛进的发展。
机器翻译这一学科有着极大的开发潜力和经济利益,开始被人们重新提起。
许多大公司开始投入资金和人力进行研究,使得机器翻译得到了复苏和重新发展的机会。
这一时期,计算语言学的一些基础工作,比如许多重要的算法等的研究已经到达了一个比较深入的阶段,对语法和语义的研究也已经有了一些比较重大的成果。
词法分析、句法分析的算法相继得到开发,并且加强了软件资源,例如电子词典的建设。
翻译方法以转换方法为代表,开始普遍采用以分析为主,辅以语义分析的基于规则方法来进行翻译,采用抽象转换表示的分层实现策略。
 抽象转换的分层实现
抽象转换的分层实现语法与算法的分开是这一时期机器翻译的另一个特点。
所谓语法与算法分开,就是指把语言分析和程序设计分开来成为两部分操作,程序设计工作者提出规则描述的方法,而语言学工作者使用这种方法来描述语言的规则。
炙手可热
世界:我们需要更精准更快速的翻译
机器翻译加入深度学习等AI技术
现在,机器翻译已经成为世界自然语言处理研究的热门。
原因之一是网络化和国际化对翻译的需求日益增大,翻译软件商业化的趋势也非常明显。
这一时期的翻译方法,我们一般称之为基于经验主义的翻译方法。
即主要基于实例和基于统计的方法,注重大规模语料库的建设,开始针对大规模的真实文本进行处理。
同时,这一阶段的研究工作开始解决一个比文本翻译更加复杂和艰难的问题——语音翻译。
由于Internet上的机器翻译系统具有巨大的潜在市场和商业利益,网上翻译机器系统也进入了实用领域的新突破阶段。
机器翻译功能越来越强大,从最初只能进行简单的单词翻译,到之后可以翻译出基本符合语法的句子,慢慢可以翻译具有一定逻辑性的句子。
现在,部分软件已经可以自主联系上下文进行翻译,翻译结果的准确性与可读性都已经取得了非常大的进步。
近年来,加入了深度学习技术等人工智能的机器翻译已经不止于简单的将一个个单词翻译成另一种语言,而是可以像人工翻译一样,不断向前回顾理解结构复杂的句子,并且联系上下文进行翻译。
最为明显的就是现在的部分机器翻译软件已经可以理解每一个代词具体指代谁,这在许多年前是不可想象的。
实现这种功能的关键,分别依赖于两种神经网络架构:一个是循环神经网络(RNN),另一个是卷积神经网络(CNN)。
目前关于两种网路架构哪种更适用于机器翻译的争论还有很多,循环神经网络与卷积神经网络我们还会在之后为大家单独介绍,至此机器翻译的脉络已为大家简略梳理完毕。
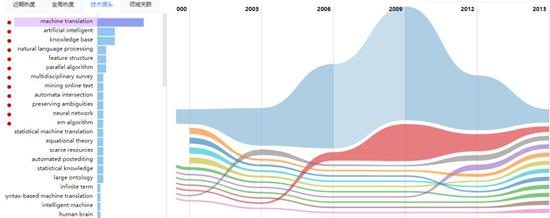 机器翻译技术源头
机器翻译技术源头实际上,机器翻译想要做好一个落地应用是很难的。因为许多人对其效果都持有着绝高的、难以完美达到的预期。
有语言学者指出,机器翻译目前没有思想,很难替代人类。
然而现在已经2018年了,Google Duplex都通过图灵测试了,未来还有什么不可能发生?
我们期待着未来的“某天”。

